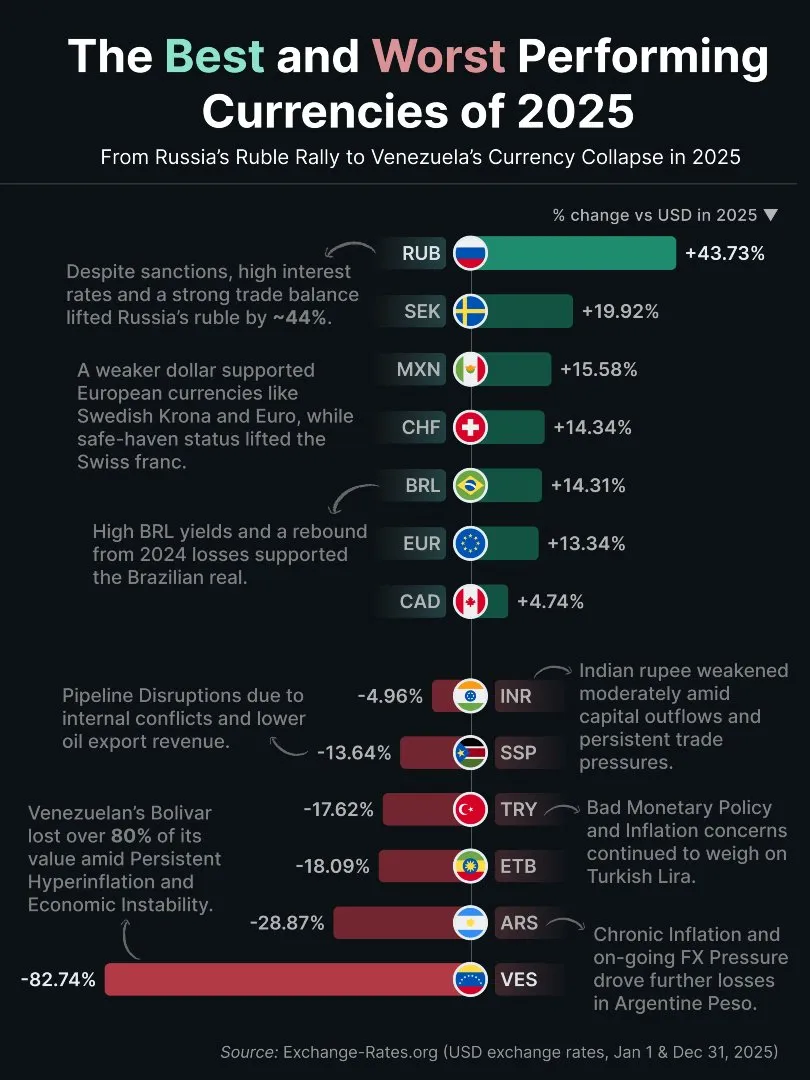
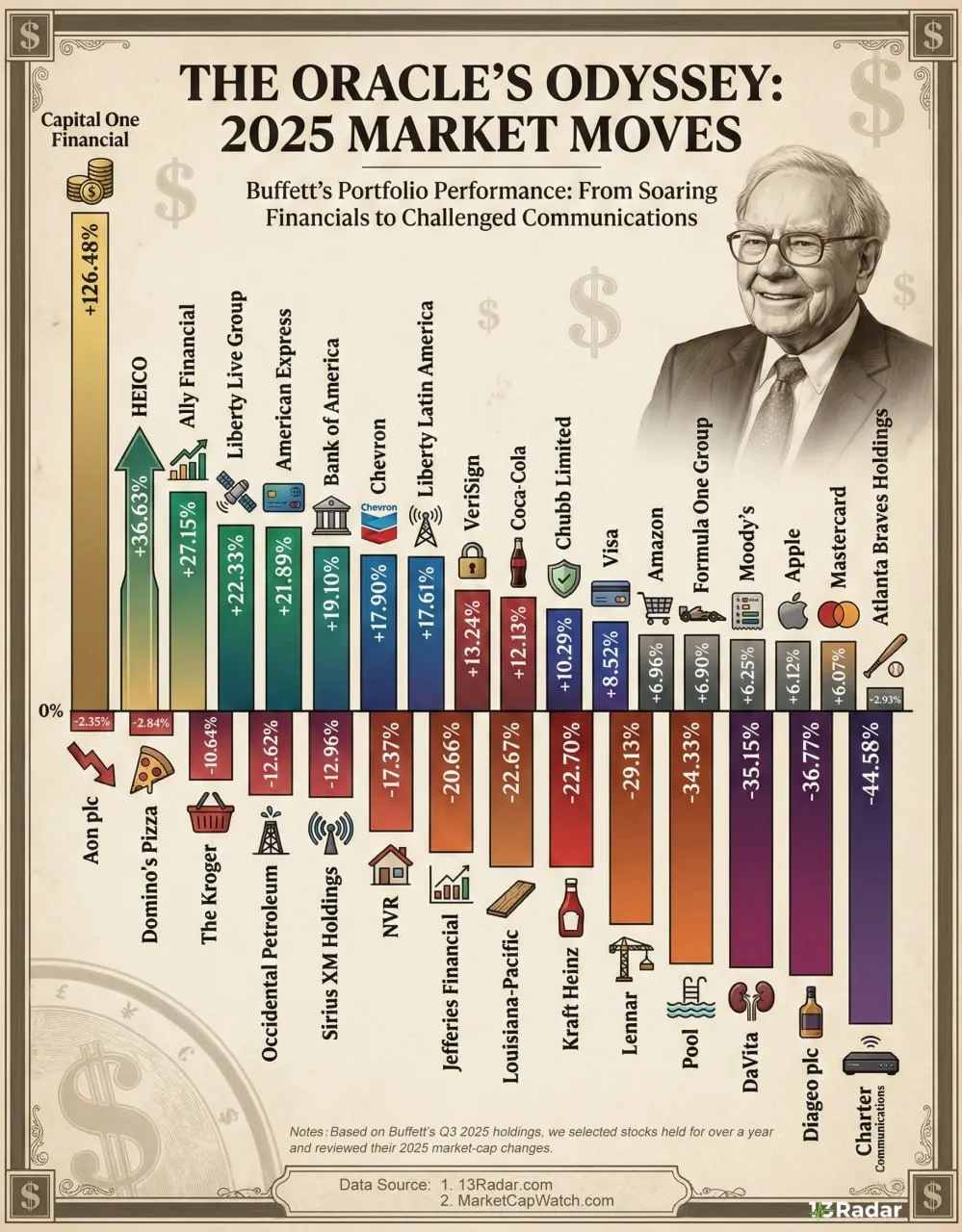
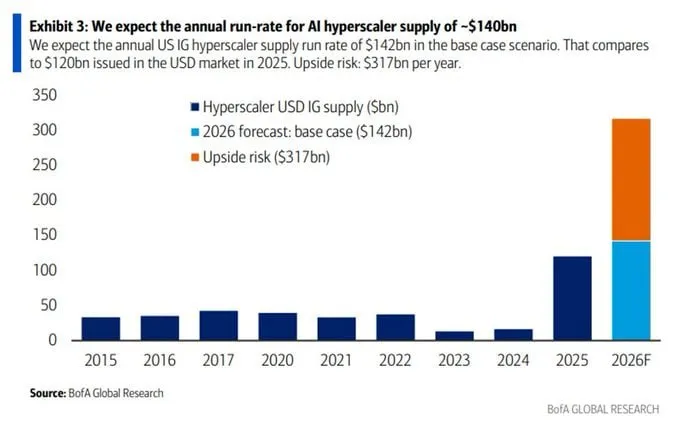
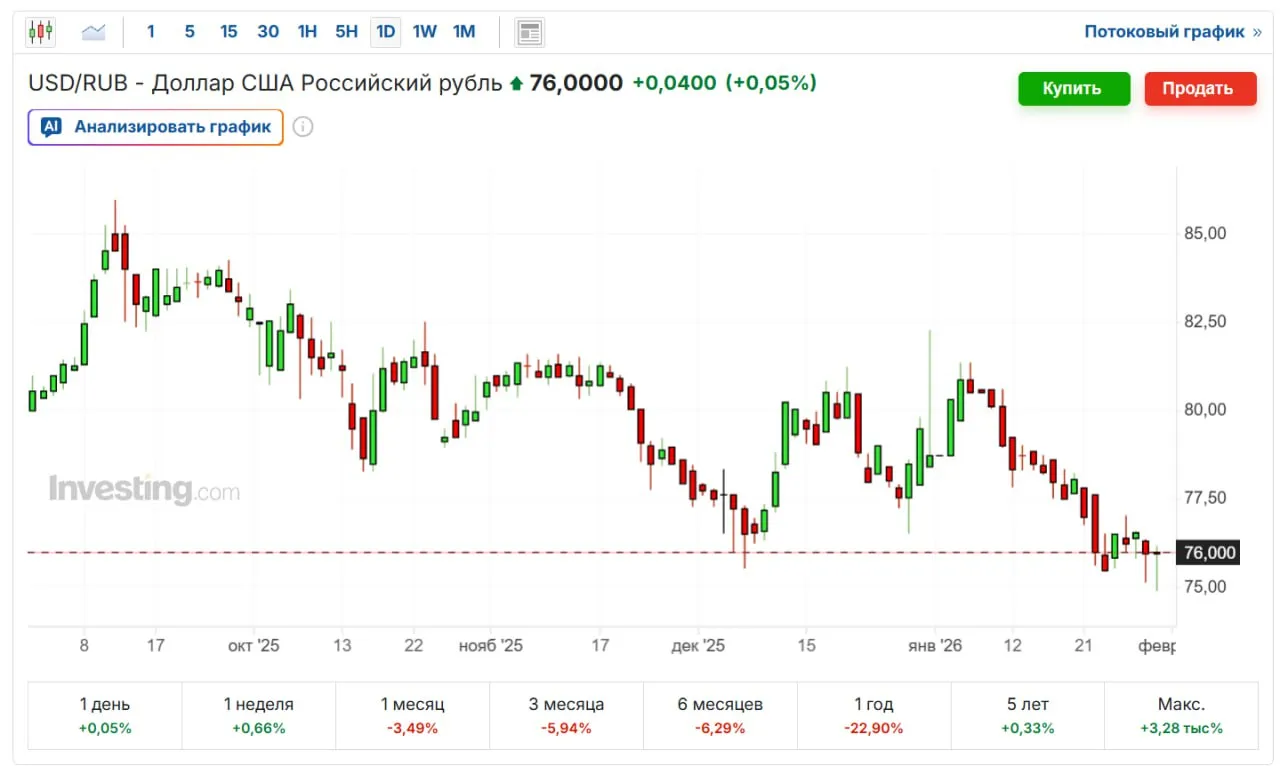
GPT искусственный интеллект меняет правила игры. Я вижу это каждый день в проектах. Здесь говорю о том, что реально важно для бизнеса и где искать точки роста.
- GPT искусственный интеллект: значение для бизнеса и точки роста
- Стратегия развития искусственного интеллекта и корпоративная подготовка
- Оценка зрелости данных и инфраструктуры
- Формирование дорожной карты и KPI для ИИ-проектов
- Организационная модель, роли и управление изменениями
- Бизнес-стратегии с использованием GPT
- Автоматизация клиентского сервиса и чат-боты
- Персонализация маркетинга и генерация контента
- Оптимизация внутренних операций и аналитики
- Технологическая архитектура и интеграция GPT
- Выбор модели: публичный API, open‑source или кастомизация
- Интеграция с CRM, ERP и BI
- Управление данными и пайплайны (ETL/ELT) для GPT-систем
- Безопасность, конфиденциальность и соответствие требованиям
- Защита данных, шифрование и изоляция окружений
- Соответствие GDPR, локальным законам и отраслевым стандартам
- Управление доступом, аудит и трассировка решений моделей
- Управление рисками: этика, предвзятость и галлюцинации
- Политики проверки фактов и механизмы мониторинга качества вывода
- Отслеживание и снижение предвзятости в данных и модели
- Объяснимость моделей и аудит решений
- Монетизация и оценка эффективности инвестиций
- Метрики ROI, KPI и экономическое обоснование проектов
- Модели монетизации продуктов на базе GPT
- Кейсы: успешные примеры внедрения GPT в разных отраслях
- Ритейл: персонализация ассортимента и поддержка клиентов
- Финансы: автоматизация аналитики и клиентского сопровождения
- Производство и логистика: планирование и оптимизация процессов
- Малый бизнес и стартапы: доступные сценарии внедрения
- Пилотные проекты, PoC и масштабирование в продакшн
- Как запустить пилот: цели, объем, сроки и команды
- Критерии успешного PoC и перехода в прод
- Масштабирование: DevOps для моделей и контроль затрат
- Управление талантами, обучение и культура использования ИИ
- Развитие навыков: промпт-инженерия и интерпретация выводов
- Система мотивации и управление изменениями в процессах
- Выбор поставщиков, партнеров и экосистема решений
- Критерии выбора вендора и модель коммерческого сотрудничества
- Сотрудничество с исследовательскими и стартап-экосистемами
- Бюджетирование, оценка стоимости и модели TCO
- Оценка стоимости владения и сценарии оптимизации расходов
- Будущее и тренды: что дальше для GPT и искусственного интеллекта в бизнесе
GPT искусственный интеллект: значение для бизнеса и точки роста
Я считаю, что GPT — это не просто инструмент для генерации текста. Это платформа для улучшения процессов. Она ускоряет принятие решений. Снижает ручной труд. Помогает персонализировать взаимодействие с клиентом. В итоге компании экономят время и деньги, а также повышают лояльность клиентов.
Главные направления роста, которые я замечаю:
- Автоматизация рутинных задач. Снижение затрат на обслуживание.
- Персонализация продуктов и маркетинга. Большее вовлечение клиентов.
- Ускорение аналитики. Быстрые инсайты из больших данных.
- Новые продукты на основе генеративных возможностей. Дополнительный доход.
Ниже простая таблица с примерами эффектов и метрик. Я часто использую её при обсуждении с руководством.
| Область | Пример выгоды | Типичная метрика |
|---|---|---|
| Клиентский сервис | Чат-боты обрабатывают запросы 24/7 | Время ответа, NPS |
| Маркетинг | Персональные письма и рекомендации | CTR, конверсия |
| Операции | Автоматизация отчетности и прогнозов | Сэкономленные часы, точность прогноза |
GPT дает шанс не только оптимизировать затраты. Он открывает новые источники ценности.
Стратегия развития искусственного интеллекта и корпоративная подготовка
Я начинаю стратегию с вопросов. Какие задачи приоритетны? Какие данные доступны? Какие риски приемлемы? Ответы формируют дорожную карту.
Важно не пытаться сразу охватить всё. Лучше выбрать несколько пилотных сценариев. Дать им четкие цели. Оценивать по результатам и масштабировать решения, которые работают.
Ключевые элементы подготовки компании, которые я рекомендую учитывать:
- Готовность данных и инфраструктуры. Без этого проекты буксуют.
- Организационная поддержка. Роли и ответственные за внедрение.
- Политики безопасности и соответствия. Согласование с юристами и безопасниками.
- План развития навыков. Промпт‑инженеры, аналитики, DevOps.
Я всегда советую фиксировать ожидания от ИИ в виде KPI и этапов. Это убирает размытость и помогает принимать решения о масштабировании.
Оценка зрелости данных и инфраструктуры
Я быстро проверяю несколько вещей. Есть ли централизованное хранилище данных. Какое качество у ключевых таблиц. Происходит ли сбор метаданных. Эти ответы показывают готовность к GPT-проектам.
- Доступность данных в нужном объёме и формате.
- Качество: пропуски, дубликаты, корректность.
- Инфраструктура: вычислительные ресурсы, сеть, безопасность.
- Процессы ETL/ELT и мониторинг пайплайнов.
Если чего-то не хватает, сначала решаем инфраструктурные вопросы. Обучение модели на плохих данных даст плохие результаты.
Формирование дорожной карты и KPI для ИИ-проектов
Я делаю дорожную карту по шагам. Сначала пилот. Потом расширение. Затем интеграция в бизнес‑процессы. Важно прописать критерии успеха заранее.
Примеры KPI, которые я предлагаю использовать:
- Операционные: экономия времени, снижение ошибок.
- Коммерческие: рост конверсии, дополнительный доход.
- Качество модели: точность, полнота, F1‑score.
- Вовлечение пользователей: adoption rate, churn после внедрения.
В дорожной карте я всегда указываю сроки, владельцев задач и точки проверки. Это помогает принимать решение о следующем шаге без эмоций.
Организационная модель, роли и управление изменениями
Я часто вижу одну и ту же проблему:нужные роли не распределены, и проекты буксуют. Лучше строить модель по принципу центральной команды и встраивания экспертов в бизнес‑юниты. Центральная команда задаёт стандарты, обеспечивает инфраструктуру и управляет рисками. Команды на местах быстро внедряют решения и проверяют гипотезы.
| Роль | Задачи |
|---|---|
| Executive Sponsor | Стратегия, финансирование, приоритеты |
| Product Owner | Бизнес‑требования, успех продукта |
| Data Engineer | Пайплайны, качество данных |
| ML/Prompt инженер | Настройка моделей, промптинг, тестирование |
| MLOps | Развёртывание, мониторинг, CI/CD |
| Compliance / Legal | Политики, соответствие, риск‑оценки |
Управление изменениями — это не только тренинги. Я рекомендую такой план действий:
- Определить владельцев процессов и KPI.
- Запустить пилот с ясными целями.
- Собирать обратную связь от пользователей каждую неделю.
- Автоматизировать шаги, которые доказали эффект.
- Обеспечить регулярные коммуникации и документацию.
Если не назначить ответственных, ИИ останется красивой идеей, а не инструментом бизнеса.
Бизнес-стратегии с использованием GPT

Я люблю подход, где стратегия проста и прагматична. Сначала ищем явные болевые точки. Потом проверяем, где GPT даёт ощутимый эффект при минимальных рисках. Приоритеты расставляем по скорости отдачи и масштабу влияния.
Ключевые направления:
- Автоматизация рутинных задач и поддержка клиентов.
- Персонализация коммуникаций и контента.
- Ускорение аналитики и принятия решений.
| Сценарий | Ожидаемый эффект |
|---|---|
| Чат‑боты | Снижение нагрузки на службу поддержки, скорость ответов |
| Генерация маркетинга | Ускорение контент‑производства, персонализация |
| Внутренняя аналитика | Экономия времени аналитиков, лучшее принятие решений |
Я рекомендую стратегию «платформа + быстрые победы». Сначала строим платформу: данные, безопасность, MLOps. Параллельно запускаем 2—3 пилота с высокой вероятностью успеха. Это даёт и опыт, и бизнес‑поддержку для масштабирования.
Автоматизация клиентского сервиса и чат-боты
Я видел, как правильно настроенный GPT‑чат уменьшал время ответа в несколько раз.
Главное — чёткая интеграция с существующими системами и сценариями эскалации. Бот решает типовые вопросы и передаёт сложные кейсы людям.
- Определите границы ответственности бота.
- Настройте handoff на человека по триггерам.
- Собирайте логи разговоров для улучшения промптов.
- Контролируйте KPI: CSAT, время ответа, разрешённые запросы.
Чат‑бот — не замена людям. Это инструмент, который делает людей эффективнее.
Технические нюансы:интенты, слоты, контекст‑менеджмент и безопасность данных. Я советую тестировать на реальных сценариях и держать систему прозрачной для оператора поддержки.
Персонализация маркетинга и генерация контента
Я использую GPT для создания текстов, адаптированных под сегменты и каналы. Модель генерирует варианты для email, лендингов и рекламных креативов. Потом мы проводим A/B‑тесты и выбираем лучшие.
| Контент | Роль GPT |
|---|---|
| Персонализированные темы и тела письма | |
| Рекламные тексты | Быстрая генерация множества вариантов |
| Соцсети | Короткие посты и адаптация под тон бренда |
Важно задать строгие шаблоны и тон общения. Я рекомендую создать набор «бренд‑правил» для промптов и верифицировать контент через человека перед публикацией.
Оптимизация внутренних операций и аналитики
GPT ускоряет рутинные процессы. Он помогает структурировать документы, готовить сводки и автоматически составлять отчёты. Это экономит время аналитиков и менеджеров.
- Автоматическая обработка входящих писем и документов.
- Генерация резюме и инсайтов по данным.
- Автоматические дашборды с объяснениями на простом языке.
- Помощь в написании кода запросов для BI и SQL‑шаблонов.
Я всегда интегрирую GPT с BI и ETL. Так модель видит актуальные данные.
Контроль качества вывода — обязательный этап. Без него выгоды будут нестабильны.
Технологическая архитектура и интеграция GPT
Я расскажу про ключевые элементы архитектуры, которые нужны для надежной работы GPT в бизнесе. Система обычно состоит из модели, слоя интеграции, хранилищ данных и мониторинга. Модель отвечает за генерацию текста. Слой интеграции связывает модель с приложениями. Хранилище держит контекст, векторные представления и логи. Мониторинг следит за качеством и затратами.
Важно правильно спроектировать потоки данных и определить точки отказа. Я советую разделять синхронные и асинхронные сценарии. Для интерактивных интерфейсов нужна низкая задержка. Для бэк-оффис задач можно обрабатывать пакеты.
- Компоненты: модель (API/контейнер), оркестратор запросов, кеши, векторное хранилище, ETL-пайплайн, логирование.
- Нефункциональные требования: доступность, масштабируемость, безопасность, контроль затрат.
- Наблюдаемость: метрики запросов, качество ответов, задержки, расходы.
Выбор модели: публичный API, open‑source или кастомизация
Выбор модели — это баланс между скоростью внедрения и контролем. Я всегда начинаю с простых вопросов: нужен ли полный контроль над данными? Нужна ли тонкая кастомизация? Какой бюджет на эксплуатацию?
| Критерий | Публичный API | Open‑source | Кастомизация (файн‑тин) |
|---|---|---|---|
| Время внедрения | Быстро | Средне | Долго |
| Контроль над данными | Низкий | Высокий | Высокий |
| Стоимость | Операционные | Инфраструктура | Высокие начальные и OPEX |
| Качество под задачу | Хорошо для общего применения | Зависит от усилий | Лучше при правильной подготовке данных |
Я обычно рекомендую стартовать с публичного API для валидации гипотез. Если появится требование по приватности или прокачке качества — переходить на open‑source или кастомизацию. Кастомизация оправдана, когда модель решает критичные задачи и приносит прямой доход.
Интеграция с CRM, ERP и BI
Интеграция — практическая часть работы. Я люблю делить её на паттерны.
Первый паттерн — real‑time для чатов и ассистентов.
Второй — batch для аналитики и генерации отчетов.
Третий — event‑driven для автоматических триггеров в CRM.
- Real‑time: webhook → gateway → модель → ответ → CRM/чарт.
- Batch: выгрузка данных → ETL → генерация/анализ → загрузка результатов.
- Event‑driven: события в очереди (Kafka) триггерят обработку через сервис с GPT.
Совет: начните с простого коннектора к CRM. Автоматизируйте 1—2 сценария и замеряйте эффект.
Для BI важно сохранять трассируемость. Результаты генерации должны попадать в DW с метаданными. Тогда аналитики смогут проверять корректность и строить отчеты на основе выводов модели.
Управление данными и пайплайны (ETL/ELT) для GPT-систем
Данные — сердце GPT‑решений. Я всегда проектирую пайплайн так, чтобы данные были чистыми, версионированными и воспроизводимыми. Для RAG (retrieval‑augmented generation) нужны векторные индексы и свежие текстовые источники.
| Шаг | Описание |
|---|---|
| Сбор | Собираем логи, документы, CRM‑записи, транзакции. |
| Очистка | Нормализация, удаление PII, приведение форматов. |
| Трансформация | Токенизация, создание эмбеддингов, агрегации. |
| Хранение | Data Lake + векторное хранилище (Milvus, Pinecone). |
| Доставка | API, кеши, индекс поиска для RAG. |
Я применяю инструменты типа Airflow, dbt, Kafka и специфичные векторные базы. Важно версионировать наборы данных и схемы эмбеддингов. Это помогает откатиться при ошибке и отследить деградацию качества.
Безопасность, конфиденциальность и соответствие требованиям
Пару слов о безопасности. Я отношусь к ней как к непрерывному процессу. Защита данных должна быть на всех уровнях.
Шифрование в покое и в транзите — базовое требование. Секреты и ключи хранят в менеджере секретов.
- Изоляция окружений: тест, стейдж, прод с разными политиками доступа.
- Шифрование: TLS для транспорта, KMS для хранения ключей.
- Логи и аудит: сохранять трассы запросов, метаданные и версии модели.
- Контроль доступа: RBAC, SSO, минимальные привилегии.
Важно: если модель обучается на чувствительных данных, лучше использовать on‑prem или VPC‑решения. Тогда вы контролируете каждый шаг.
Совместимость с требованиями — обязательна. Мы добавляем механизмы удаления данных по запросу и маскирование PII на этапе ETL. Это упрощает соответствие законам и отраслевым стандартам. Я тестирую систему на инциденты и регулярно провожу ревью конфигурации безопасности.
Защита данных, шифрование и изоляция окружений
Я всегда начинаю с простого: какие данные у нас есть и кто к ним может получить доступ. Дальше ставлю приоритет на шифрование в движении и в покое. TLS для передачи. AES-256 или эквивалент для хранилищ. Ключи держим отдельно и управляем ими через KMS. Никаких ключей в коде или в общих репозиториях.
Изоляция окружений — следующий шаг. Продакшн, тест и разработка должны быть разделены. Использую VPC, сетевые ACL и сегментацию. Контейнеры и виртуальные машины дают runtime-изоляцию. Для особо чувствительных данных рассматриваю аппаратные окружения и HSM.
| Уровень | Преимущества | Когда применять |
|---|---|---|
| Шифрование в покое | Защищает данные при хранении | Базы данных, бэкапы, файлы |
| Шифрование в транспорте | Защищает трафик между сервисами | API, межсервисные вызовы |
| Аппаратные ключи / HSM | Максимальная защита ключей | Критичные креденшнлы, подписи |
Наконец, минимизирую объем данных, отправляемых в модель. Личная информация токенизируется или анонимизируется. Логирую только нужные поля и ставлю строгие политики удаления.
Безопасность — не галочка в чек-листе. Это непрерывная привычка в разработке и эксплуатации.
Соответствие GDPR, локальным законам и отраслевым стандартам
Я подхожу к теме просто: сначала определяю роль — контролер или процессор. От этого зависят обязательства. Для EU-данных учитываю права субъекта: доступ, исправление, удаление. Делаю DPIA, если обработка рискованная.
Трансграничная передача данных требует внимания. Использую стандартные договорные положения или подобные механизмы. Веду реестр операций обработки. Храню доказательства согласий и оснований обработки.
- Собираю минимум данных для цели.
- Псевдонимизация где возможно.
- Оповещение о нарушении в установленные сроки.
- Аудитные журналы для доказательств соответствия.
| Требование | Практическая мера |
|---|---|
| Права субъекта | Интерфейсы для запросов, процессы удаления |
| DPIA | Оценка рисков и смягчающие меры |
| Международные передачи | Контракты, SCC, локализация данных |
Отраслевые стандарты добавляют требования. Для здравоохранения это, например, ограничение доступа и дополнительные логи. Для финансов — строгая аудитория и хранение транзакционных записей. Я всегда документирую соответствие и периодически пересматриваю процессы.
Управление доступом, аудит и трассировка решений моделей
Доступы делю по ролям и минимизирую привилегии.
RBAC — база. MFA — обязательно для админов и девопс. Для сервисов использую короткоживущие токены и частую ротацию ключей.
Логи нужны не только для отладки. Они нужны для безопасности и расследований. Логирую запросы к модели, но редактирую и маскирую PII. Храню версии модели и набор данных, чтобы можно было восстановить контекст при инциденте.
| Тип лога | Назначение |
|---|---|
| Аутентификация и доступ | Проверка прав и расследование |
| Ввод/вывод модели (редактируемый) | Анализ ошибок и воспроизведение инцидентов |
| Системные логи | Мониторинг производительности и сбоев |
- Версионирование моделей и данных.
- Метаданные о происхождении данных (provenance).
- Регулярные аудиты прав и ревью привилегий.
- Уведомления при аномалиях доступа.
Трассировка решений модели должна быть доступна. Я сохраняю объяснения вывода там, где это требуется. Это помогает в спорных случаях и для улучшения модели.
Управление рисками: этика, предвзятость и галлюцинации
Для меня управление рисками — это совокупность практик, а не одиночная оценка. Я формирую реестр рисков, ставлю приоритеты и связываю их с бизнес-целями. Риски делю на технические, правовые и репутационные.
Этика в ИИ — это правила поведения и проверки. Я внедряю принципы прозрачности и ответственности. В проектах всегда предусмотрен человек в цикле принятия решений. Автоматизацию не оставляю без контроля.
Предвзятость и галлюцинации требуют отдельных мер. Для предвзятости — аудит наборов данных, балансировка и тесты на разные группы пользователей.
Для галлюцинаций — механизм проверки фактов и выход на источники данных. Я ставлю метрики, по которым оцениваю уровень риска и качество вывода.
Искусственный интеллект не отменяет ответственность. Он меняет процессы. Нужно управлять этим изменением.
Политики проверки фактов и механизмы мониторинга качества вывода
Я делаю несколько уровней проверки. Первый — автоматические фильтры и сравнение с доверенными источниками. Второй — человек верификатор для критичных ответов. Третий — статистический мониторинг метрик качества.
Внедряю RAG (retrieval-augmented generation) там, где важны факты. Модель отвечает и сразу даёт ссылки на источники. Если источник отсутствует, система помечает ответ как непроверенный.
| Метрика | Что измеряет | Действие при отклонении |
|---|---|---|
| Процент проверяемых ответов | Доля ответов с подтверждением из источников | Увеличить RAG-coverage, добавить источники |
| Частота галлюцинаций | Доля явно неверных утверждений | Промежуточная фильтрация, дообучение, ручная верификация |
| Время реакции на инцидент | Как быстро исправляем ошибки | Авто-алерты, SLA для команды поддержки |
- Автоматические чекеры фактов и cross-check с базами знаний.
- Выборочные ручные ревью и обратная связь в цикл обучения.
- Логи сложности запросов и оценки уверенности модели.
- Алерты при росте жалоб или снижении метрик качества.
Практика показывает: простая автоматизация + человеческая проверка дают лучший баланс скорости и надежности. Я строю процесс так, чтобы ошибки исправлялись быстро, а данные для улучшения модели попадали в цикл дообучения.
Отслеживание и снижение предвзятости в данных и модели
Я всегда начинаю с аудита данных. Смотрю, какие группы представлены, какие сценарии отсутствуют, где есть аномалии. Простая статистика по распределению признаков часто показывает очевидные перекосы. После этого проверяю модель на критичных сегментах. Тестирую поведение на контролируемых примерах и на синтетических кейсах, где меняю одну переменную и смотрю ответ.
Меры снижения предвзятости я применяю по этапам. На уровне данных фильтрую явные искажения. На уровне обучения использую взвешивание и стратификацию. На уровне вывода добавляю постобработку и правила валидации. Важно держать мониторинг в продакшне. Любая модель со временем может «сдвинуться», когда меняется пользовательская база или источник данных.
- Регулярные метрики: различие показателей по группам, false positive/false negative по сегментам.
- Тесты на отражённость: парные примеры, контрастные подсказки, контрольные наборы.
- Автоматические алерты: рост дисбаланса, ухудшение качества в целевых группах.
Инструменты помогут, но без процедур и ответственных ничего не работает. Я определяю владельцев данных, внедряю чек-листы для новых датасетов и прошу команду проводить ретро при выявлении инцидентов. Включаю людей из разных подразделений. Это уменьшает риск, что важную проблему заметит только модель.
Объяснимость моделей и аудит решений

Я считаю, что объяснимость — это не модное слово, а рабочий инструмент. Пояснения нужны и пользователям, и аудитории внутри компании. Для бизнес-процесса важно понимать, почему модель приняла решение. Я использую как локальные методы объяснений, так и глобальные отчёты по модели.
На практике применяю следующие подходы: LIME и SHAP для объяснений отдельных предсказаний, attention‑визуализации для текстовых моделей, контрфактные примеры для проверки логики. Кроме этого делаю модель-карты и документацию с описанием данных, ограничений и сценариев использования.
Объяснимость облегчает аудит и снижает юрриски. Без объяснимости сложно защищать решения перед регулятором или клиентом.
Для аудита я готовлю чек-лист и журнал событий.
В чек-листе — источники данных, даты обучения, валидационные метрики, известные ограничения, и ответственные лица. Журнал фиксирует входные данные, вывод модели и применённые объяснения. Это ускоряет расследование инцидентов и помогает повторяемости экспериментов.
Монетизация и оценка эффективности инвестиций
Когда я смотрю на проект с GPT, первое, что делаю — привожу метрики к деньгам. Без этого трудно убедить руководство. Монетизация и оценка эффективности идут рука об руку. Надо понимать, как проект влияет на выручку, экономию или удержание клиентов.
Метрики ROI, KPI и экономическое обоснование проектов
Я не верю в одну универсальную метрику. Беру набор KPI, которые напрямую связаны с бизнес-целями. Для чат-ботов это сокращение времени обработки и снижение нагрузки операторов. Для маркетинга — рост конверсии и средний чек. Для внутренних процессов — уменьшение ошибок и ускорение аналитики.
- Базовые KPI: время обработки, стоимость контакта, NPS, конверсия, churn.
- Финансовые KPI: экономия FTE, прирост выручки, снижение операционных затрат.
- Качество: точность, полнота, процент корректных ответов.
Для оценки ROI использую простую формулу: (выгода — затраты) / затраты. Выгоду считаю как суммарную экономию и дополнительную выручку за год. Важно учитывать не только прямые затраты на модели, но и интеграцию, сопровождение и обучение персонала. Я всегда делаю сценарии: консервативный, реалистичный и агрессивный. Это помогает принимать решения под риск.
ROI — это не только техническая эффективность. Это подтверждение ценности проекта для бизнеса.
Модели монетизации продуктов на базе GPT
Я обычно рассматриваю несколько моделей и комбинирую их в продукте. Для стартапа часто подходят подписки и оплата за использование. Для корпоративных клиентов — лицензии, white‑label и доступ по API с SLA. Есть и результатно-ориентированные контракты: платишь за улучшение метрики, например снижение churn.
| Модель | Описание | Плюсы | Минусы |
|---|---|---|---|
| Подписка | Ежемесячная/годовая плата за доступ к сервису | Предсказуемый доход | Нужна ценность, чтобы удерживать клиентов |
| Плата за запрос | Оплата по использованию API или по сессии | Честная модель для клиентов с нерегулярным трафиком | Доход нестабилен, сложнее прогнозировать |
| Лицензирование/White‑label | Продаётся решение под бренд клиента | Высокая маржа в B2B | Требует кастомизации и поддержки |
| Результат-ориентированные контракты | Оплата при достижении KPI | Сильный стимул для эффективности | Риск невыплаты при неверном таргете метрик |
Важный момент: упаковка ценности. Не продавайте просто модель. Продавайте решение: интеграцию, гарантию качества, обучение команды и поддержку. Я часто предлагаю три уровня сервиса. Базовый, расширенный и enterprise. Это упрощает выбор клиента и повышает LTV.
Кейсы: успешные примеры внедрения GPT в разных отраслях
Я люблю разбирать реальные примеры. Они короткие и живые. Ниже примеры, где GPT давал конкретный эффект.
- Ритейл. Внедрили чат-помощника для подбора товара и рекомендаций. Результат: рост среднего чека на 8% и сокращение времени ответа на 70%. Бот интегрирован в сайт и мессенджеры. Человек вмешивается только в сложных случаях.
- Финансы. Автоматизация первичной аналитики заявок и ответов клиентам. Машина подготовляет карточку клиента и контекст для менеджера. Скорость обработки заявок выросла в 3 раза. Число ошибок при ручном вводе снизилось.
- Производство и логистика. Генерация прогнозов спроса и оптимизация расписаний. Команда совместила GPT с классическими моделями и получила улучшение точности прогноза на 12%. Это позволило снизить издержки хранения и ускорить оборот склада.
- Малый бизнес и стартапы. Небольшая юридическая фирма использовала GPT для подготовки шаблонов договоров и первичных ответов клиентам. Экономия времени сотрудников составила до 20 часов в неделю, что позволило взять больше клиентов без найма.
| Отрасль | Проблема | Результат |
|---|---|---|
| Ритейл | Низкий AOV, долгие ответы | +8% AOV, —70% время ответа |
| Финансы | Длительная обработка заявок | ×3 скорость обработки |
| Производство | Ошибки в прогнозах | +12% точность прогноза |
| Малый бизнес | Ограниченные ресурсы | Экономия 20 ч/неделя |
Эти кейсы показывают один общий подход: фокус на конкретной боли, быстрый пилот и измеримые KPI. Я всегда рекомендую начинать так же. Маленькие победы быстрее убеждают скептиков и открывают путь к масштабированию.
Ритейл: персонализация ассортимента и поддержка клиентов
Я вижу в ритейле две главные точки роста благодаря GPT.
Первая — глубокая персонализация ассортимента. Модель анализирует поведение покупателя, сочетает данные о продажах и трендах. Затем предлагает товары и комплекты, которые реально продаются.
Вторая — поддержка клиентов. Чат-боты отвечают быстро и естественно. Они обрабатывают возвраты, подбирают размеры и дают советы по сочетаниям. Это снижает нагрузку на колл-центр и повышает конверсию.
Ниже простая таблица с примерами и эффектом:
| Сценарий | Что делает GPT | Эффект |
|---|---|---|
| Рекомендации на сайте | Подбирает товары на основе поведения | Увеличение среднего чека |
| Генерация карточек товара | Автоподготовка описаний и тегов | Снижение затрат на контент |
| Чат-поддержка | Ответы и эскалация к человеку | Сокращение времени ожидания |
- Начните с малого: рекомендации для одной категории.
- Отслеживайте метрики: CTR, AOV, время ответа.
- Плавно масштабируйте и добавляйте интеграции с CRM.
Финансы: автоматизация аналитики и клиентского сопровождения
В финансах GPT помогает быстро превращать данные в инсайты. Я использую модели для сводных отчетов, объяснений метрик и для создания клиентских писем. Модель умеет генерировать интерпретацию квартальных данных и предлагать сценарии. Это экономит аналитикам время и делает коммуникацию с клиентом яснее.
Примеры применений:
- Автоматическое резюме отчетов и выделение аномалий.
- Предварительная оценка кредитного риска на основе текстовых данных.
- Чат-ассистент для клиентов по счетам и платежам с логикой эскалации.
Важно соблюдать осторожность с приватными данными и логами. Я всегда рекомендую маскировать чувствительную информацию перед отправкой в модель и вести аудит решений.
Производство и логистика: планирование и оптимизация процессов

В производстве GPT полезен там, где есть текст и правила. Я применяю модели для планирования обслуживания, интерпретации отчетов датчиков и составления инструкций. Они помогают прогнозировать спрос на основе текстовых факторов и оптимизировать расписания. Это снижает простой и улучшает прогнозы запасов.
Конкретные кейсы:
- Прогнозирование спроса с учётом отчетов продаж и сезонности.
- Предиктивное обслуживание: анализ сообщений о неисправностях.
- Автоматическая генерация инструкций и контрольных списков для операторов.
Интеграция с MES и ERP критична. Я настраиваю пайплайны так, чтобы модель получала предобработанные данные. Только так прогнозы становятся стабильными и полезными в операционной деятельности.
Малый бизнес и стартапы: доступные сценарии внедрения
Малому бизнесу не нужны сложные машины. Мне нравится предлагать простые решения, которые дают быстрый эффект. Чат-бот на сайте, автоматический генератор постов в соцсетях, помощь в написании коммерческих предложений. Это недорого и быстро.
Доступные варианты внедрения:
- Готовые SaaS-решения с подключением GPT через API.
- No-code платформы для создания чат-ботов и автоматизации писем.
- Шаблоны для описаний товаров и рекламных текстов.
Я советую начинать с одного сценария и отслеживать результат. Обычно инвестиции окупаются через улучшение общения с клиентами и снижение затрат на создание контента.
Пилотные проекты, PoC и масштабирование в продакшн
Я часто запускаю пилоты по одной простой причине: быстро проверять гипотезы. Пилот должен иметь понятную цель.
- Объем данных — ограниченный.
- Сроки — короткие.
- Команда — небольшая и кросс-функциональная.
Так мы быстро видим, работает ли идея и стоит ли масштабировать.
Шаги для пилота:
- Определить KPI и критерии успеха.
- Выбрать узкий сценарий для теста.
- Подготовить тестовые данные и политику безопасности.
- Запустить MVP и собирать метрики.
- Принять решение: доработать, масштабировать или остановить.
Лучше маленький рабочий пилот, чем большая теория. Я всегда начинаю с реального результата.
Таблица отличий PoC и продакшн:
| Аспект | PoC | Продакшн |
|---|---|---|
| Масштаб | Ограниченный | Высокий |
| Требования к SLA | Низкие | Строгие |
| Мониторинг | Базовый | Непрерывный, с алертами |
| Бюджет | Минимальный | Планируемый и оптимизированный |
При переходе в продакшн я уделяю внимание DevOps и MLOps. Нужен автоматический деплой, мониторинг качества вывода и контроль затрат на инфрастуктуру. Без этого пилот может встать на этапе реального трафика.
Как запустить пилот: цели, объем, сроки и команды
Когда я запускаю пилот, я начинаю с одной ясной цели. Цель должна быть измеримой и реалистичной. Я ограничиваю объем. Лучше протестировать узкую задачу, чем тянуть весь бизнес-процесс.
Сроки ставлю короткие. Обычно 4—8 недель. Это позволяет быстро получить выводы и не тратить ресурсы зря.
Команда небольшая и кросс-функциональная. В ней есть продуктовый владелец, инженер данных, ML-инженер, devops и представитель бизнеса. Я фиксирую ответственность заранее.
Ниже — краткий чеклист и пример таймлайна.
- Определить гипотезу и KPI
- Подготовить минимальный набор данных
- Выбрать модель и интеграционный прототип
- Запустить и собрать метрики
- Оценить риски и безопасность
| Этап | Длительность | Ответственный |
|---|---|---|
| Подготовка данных | 1—2 недели | Инженер данных |
| Разработка прототипа | 2—3 недели | ML-инженер |
| Тестирование и итерации | 1—2 недели | Продукт/Бизнес |
Критерии успешного PoC и перехода в прод
Я оцениваю PoC по простым и понятным критериям. Если показали улучшение по KPI и нет критичных рисков — это хороший знак. Важно смотреть не только на точность модели. Надо оценить интеграцию, задержки, расходы и влияние на процессы.
- Метрики: улучшение ключевых показателей на заранее заданный процент.
- Техническая стабильность: время отклика и устойчивость под нагрузкой.
- Качество данных и повторяемость результатов.
- Соответствие требованиям безопасности и комплаенса.
- Экономика: прогнозируемая стоимость на уровень продакшна.
PoC должен ответить на один вопрос: стоит ли это масштабировать?
Масштабирование: DevOps для моделей и контроль затрат
Масштабирование я начинаю с автоматизации. Нужны CI/CD для моделей, контейнеризация и инфраструктура для автоскейлинга. Мониторинг обязателен. Нужно следить за качеством предсказаний и метриками ресурсов.
Контроль затрат — отдельная тема. Я использую несколько рычагов, чтобы снизить расходы без потери качества.
- Кэширование ответов и батчинг запросов.
- Квантование и оптимизация моделей для ускорения.
- Гибридная архитектура: критичные запросы на локальном инстансе, остальное через облако.
- Автоматическое отключение неиспользуемых ресурсов.
| Мера | Эффект |
|---|---|
| Кэширование | Снижение числа вызовов API |
| Квантование | Меньше памяти и быстрее инференс |
| Планирование задач | Оптимизация затрат на вычисления |
Управление талантами, обучение и культура использования ИИ
Я считаю, что успех ИИ-проекта зависит не только от технологий. Люди важнее. Я строю культуру, где экспериментирование поощряется. Ошибки рассматриваем как источник обучения. Важна прозрачность: объясняю, зачем нужны модели и как они работают.
Набираю команды смешанного профиля. Это не только ML-инженеры. Нужны аналитики, продуктовые менеджеры и специалисты по безопасности. Я организую регулярные воркшопы. На них команда вместе разбирает кейсы и учится интерпретировать выводы моделей.
- Внутренние курсы и микрообучение по промпт-инженерии.
- Практики code review и peer-review моделей.
- Система мотивации за успешные эксперименты и экономию ресурсов.
Лучше маленькая команда, которая понимает ИИ, чем большая, которая боится его.
Развитие навыков: промпт-инженерия и интерпретация выводов
Промпт-инженерия — это навык, который учится на примерах. Я провожу практические занятия. Даю задания с разными целями. Учим формулировать промпты, тестировать и сравнивать ответы.
Интерпретация выводов требует критического мышления. Я учу команду верифицировать факты и оценивать уверенность модели. Полезны матрицы проверки и шаблоны вопросов, которые помогают выявлять галлюцинации.
- Упражнения: A/B тесты промптов.
- Практика: сценарии с контрольными данными.
- Инструменты: логирование запросов и визуализация ответов.
Система мотивации и управление изменениями в процессах
Я считаю, что внедрение ИИ превращает не только технологию, но и поведение людей. Нужно продумать мотивацию так, чтобы сотрудники хотели использовать новые инструменты. Я обычно разделяю подход на три части: цели, вознаграждение и поддержка.
Цели — понятные KPI по времени отклика, качеству решений и уровню автоматизации.
Вознаграждение — как финансовое, так и нематериальное: публичные признания, карьерные бонусы, участие в проектах.
Поддержка — обучение и наставничество в первые месяцы после запуска.
Важно назначить «чемпионов изменений» в командах. Они показывают пример и помогают коллегам. Я также рекомендую регулярные ретроспективы и быстрые итерации процессов. Так ошибки фиксируются сразу. И внедрение воспринимается как эволюция, а не как приказ сверху.
Выбор поставщиков, партнеров и экосистема решений
Когда я выбираю поставщика, смотрю шире, чем на цену или маркетинг. Мне важна экосистема вокруг решения. Это и интеграции, и сообщества, и сервисы поддержки. Понимаю, что одна платформа редко закрывает все задачи. Поэтому ищу партнёров, которые легко стыкуются с CRM, BI и пайплайнами данных.
Я предпочитаю гибкие модели сотрудничества. Хочу возможность начать с пилота, затем масштабировать. Вендор должен предоставлять прозрачные SLA, безопасность данных и инструменты мониторинга. Для меня важна также способность партнёра помогать в оптимизации затрат и адаптации модели под наши данные.
Критерии выбора вендора и модель коммерческого сотрудничества
Я использую чеклист из пяти ключевых критериев. Это функциональность, безопасность, стоимость, поддержка и гибкость интеграции. Оцениваю каждую позицию по практическим тестам и кейсам. Ниже табличка с типичными параметрами, которые я сравниваю при выборе.
| Критерий | Что проверяю |
|---|---|
| Функциональность | Набор API, кастомизация, latency |
| Безопасность | Шифрование, изоляция окружений, соответствие стандартам |
| Стоимость | Модель оплаты, скрытые расходы, тарифы на инференс |
| Поддержка | Реакция на инциденты, доступ к экспертам |
| Интеграция | Готовые коннекторы, SDK, кастомные решения |
Коммерчески я предпочитаю поэтапную модель: пилот + оплата по результатам + подписка на поддержку. Это снижает риски и выравнивает интересы сторон.
Сотрудничество с исследовательскими и стартап-экосистемами
Я часто инициирую сотрудничество с университетами и стартапами. Это даёт доступ к свежим идеям и узкой экспертизе. Малые команды двигают инновации быстрее. Университеты дают методологию и талантливых студентов.
Форматы работы разные. Это совместные PoC, гранты, инкубаторы, хакатоны. Я люблю быстрые пилоты на 6—8 недель. Они показывают потенциал без больших вложений. Иногда выгодно предложить стартапу долю в проекте или рынок для тестирования продукта.
Сильный партнерский альянс даёт доступ к идеям, которые внутри компании не появятся.
Бюджетирование, оценка стоимости и модели TCO
Я считаю, что бюджет на ИИ нужно считать честно и детально. В TCO включаю не только лицензии, но и инфрастуктуру, данные, сотрудников и эксплуатацию. Часто основная статья затрат — инференс в продакшн при масштабной нагрузке. Это важно учитывать заранее.
Ниже привожу основные категории расходов и советы по оптимизации.
| Категория | Что учитывать | Как оптимизировать |
|---|---|---|
| Лицензии и подписки | API, платные модели, ПО | Выбирать модель по этапам, переговоры о скидках |
| Инфраструктура | Обучение, инференс, хранение данных | Использовать спотовые инстансы, автоскейлинг, оптимизированные модели |
| Данные и интеграция | Сбор, очистка, ETL/ELT | Автоматизация пайплайнов, реюз данных |
| Персонал | Разработчики, ML-инженеры, аналитики | Смешанные команды, аутсорс частей работ |
| Эксплуатация | Мониторинг, безопасность, обновления | Автоматизация мониторинга, чёткие SLA |
Важно прогнозировать ROI на 12—24 месяца. Я рекомендую строить три сценария: консервативный, базовый и оптимистичный. Это помогает понять, когда проект станет прибыльным. Не забывайте о резервах на поддержку и доработки после запуска.
Оценка стоимости владения и сценарии оптимизации расходов
Когда я считаю стоимость владения (TCO) для GPT-проекта, я смотрю за несколькими категориями расходов. Сначала это вычислительные ресурсы для инференса и обучения. Потом хранилище данных и передачу. Лицензии API и подписки на платформы тоже важны. Нельзя забывать про команду: инженеры, дата-сайентисты, операторские расходы и сопровождение. Добавляю расходы на безопасность, соответствие и резервирование.
| Компонент | Что влияет на цену | Как оптимизировать |
|---|---|---|
| Вычисления | Мощность GPU/CPU, время инференса | Квантизация, батчинг, кэширование |
| Хранилище | Объем данных, версия моделей | Архивация, дедубликация, retention-политики |
| Лицензии и API | Тарифы провайдеров, вызовы API | Гибридная архитектура, open-source |
| Персонал | Часы разработки и поддержки | Автоматизация, переиспользуемые пайплайны |
Практические сценарии оптимизации:
- Выбирать модель по задаче. Легкая модель дешевле и быстрее. Для критичных задач — мощнее, но с контролем расходов.
- Использовать кэширование ответов и батчинг запросов. Это сразу снижает нагрузку на инференс.
- Применять квантизацию и distillation. Меньше параметров — меньше затрат при похожем качестве.
- Хранить только нужные данные. Сокращать retention там, где это возможно.
- Сравнивать публичные API и self-host. Часто гибрид дает оптимальный TCO.
Совет: сначала оптимизируйте архитектуру и процессы. После этого уже вкладывайтесь в улучшение качества модели.
Будущее и тренды: что дальше для GPT и искусственного интеллекта в бизнесе
Я вижу несколько ясных трендов. Модели станут мультимодальными и лучше понимать контекст. Это значит, что текст, изображение и звук будут обрабатываться вместе. Для бизнеса это новые сценарии: визуальная поддержка клиентов, автоматический разбор документов, голосовые помощники с пониманием контекста.
Продолжится вертикализация. Появятся отраслевые модели с знанием медицины, права, логистики. Они дадут точные ответы без долгой дообучки. Одновременно растет внимание к приватности. Функции на устройстве и федеративное обучение станут привычными. Это снизит риски утечек и сократит трафик.
- Retrieval-augmented generation и встраивание баз знаний в модели.
- Инструменты explainability и аудит решений моделей как обязательная часть производства.
- Композиция сервисов: микросервисы ИИ, которые легко заменять и масштабировать.
- Экономика промптов: рынки готовых промптов и шаблонов для бизнес-задач.
Я советую не ждать чудес. Начинайте с небольших проектов, тестируйте гипотезы, переводите успешные кейсы в продакшн. Тот, кто быстро наладит процесс обучения, развёртывания и контроля качества, получит преимущество. Будущее за теми, кто умеет сочетать технологии и реальные бизнес-процессы.